



Was ist der größte „Painpoint“ für Führungskräfte in Unternehmen?
Gartner, das weltweit größte IT-Forschungsunternehmen, gibt eine klare Antwort: die Volatilität der Nachfrage.
Zu viele Faktoren – angefangen bei der Wetterschwankungen bis hin zu Posts von Social-Media-Influencern – wirken sich auf Käufer aus und führen dazu, dass sie ihre Meinung häufig ändern. Schlimmer noch: Dinge, die die Absichten der Kunden verändern, passieren ganz unerwartet.
Denken Sie zum Beispiel an die jugendliche Klimaaktivistin Greta Thunberg. Ihr Protest, aus Umweltgründen nicht mehr zu fliegen, löste die „Flight Shame“-Bewegung aus.
Es gibt keinen Zauberstab, um Szenarien wie den „Thunberg-Effekt“ vorherzusagen. Aber es gibt Technologien, um die Genauigkeit der Nachfrageprognose zu verbessern. Um ehrlich zu sein, wird sie nie 100 Prozent präzise sein, denn sind sie präzise genug, um Ihnen als Unternehmen zu helfen, Ihre Geschäftsziele zu erreichen.
In diesem Blogbeitrag werden wir Ihnen die Möglichkeiten aktueller Prognosemethoden skizzieren.
Der Stellenwert und die Bedeutung von Prognosen in der Bedarfs- und Angebotsplanung
Wie Bedarfsprognosen die Effizienz steigern: Grundlagen und Methoden
Die Bedarfsprognose ist die Schätzung der wahrscheinlichen zukünftigen Nachfrage nach einem Produkt oder einer Dienstleistung. Der Begriff wird oft austauschbar mit der Bedarfsplanung verwendet, doch letztere ist ein umfassenderer Prozess, der mit der Prognose beginnt, aber nicht auf diese beschränkt ist.
Laut dem Institute of Business Forecasting and Planning (IBF) werden bei der Bedarfsplanung „Prognosen und Erfahrungswerte eingesetzt, um die Nachfrage nach verschiedenen Artikeln an verschiedenen Punkten der Lieferkette zu schätzen.“ Zusätzlich zu den Schätzungen nehmen Bedarfsplaner an der Bestandsoptimierung teil, stellen die Verfügbarkeit der benötigten Produkte sicher und überwachen die Differenz zwischen Prognosen und tatsächlichen Verkäufen.
Die Bedarfsplanung ist der Ausgangspunkt für viele andere Aktivitäten, wie z. B. Lagerhaltung, Versand, Preisprognosen und insbesondere die Angebotsplanung, die auf die Deckung des Bedarfs abzielt und dazu Daten über den voraussichtlichen Wunsch der Kunden benötigt.
Hier kehren wir wieder zur Prognose zurück. So nah wie möglich an der Realität zu sein, ist der Schlüssel zur Verbesserung der Effizienz in der gesamten Lieferkette. Doch wie erreicht man die höchstmögliche Genauigkeit? Die Antwort hängt vom Unternehmenstyp, den verfügbaren Ressourcen und den Zielvorgaben ab.
Vergleichen wir die vorhandenen Optionen: traditionelle statistische Prognosen, Algorithmen für maschinelles Lernen, Predictive Analytics, welches beide Ansätze kombiniert, und Demand Sensing als unterstützendes Tool.
Klassische statistische Prognosen:
Eignen sich für stabile Märkte, jedoch nicht für Veränderungen.
Traditionelle statistische Methoden (TSM) gibt es schon seit Ewigkeiten und sie sind nach wie vor ein fester Bestandteil von Prognoseprozessen in der Produktion und im Handel.
Der Unterschied zu früheren Berechnungen besteht lediglich darin, dass diese inzwischen automatisch von Softwarelösungen durchgeführt werden. Zum Beispiel können in Excel Zeitreihenprognosen für Umsätze und Trends erstellt werden.
Um die Zukunft zu prognostizieren, nutzt die Statistik Daten aus der Vergangenheit. Deshalb werden statistische Prognosen oft als „Historische Auswertung“ bezeichnet. Traditionelle Prognosen sind immer noch die populärste Methode, um Verkäufe vorherzusagen. In der Regel lassen sich Bedarfsplanungslösungen, die auf statistischen Verfahren basieren, nahtlos in Excel und bestehende Enterprise Resource Planning (ERP)-Systeme durchführen, ohne dass zusätzliches technisches Fachwissen erforderlich ist. Die fortschrittlichsten Systeme können Saisonalität und Markttrends berücksichtigen sowie zahlreiche Methoden zur Feinabstimmung der Ergebnisse anwenden.
Zu beachtende gilt, dass eine wichtige Voraussetzung für die statistische Vorhersagegenauigkeit die Stabilität des Marktes ist. Die Auswertung geht davon aus, dass sich die Geschichte wiederholt: Situationen, die vor zwei oder drei Jahren aufgetreten sind, werden sich wiederholen.
Bedarfsmuster, die statistisch gut bemessen werden können:
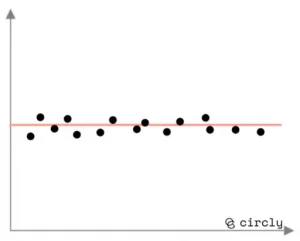
Constant demand curve
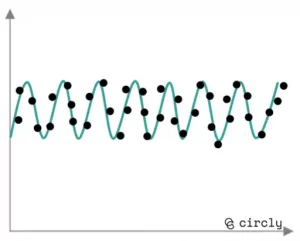
Seasonal demand pattern
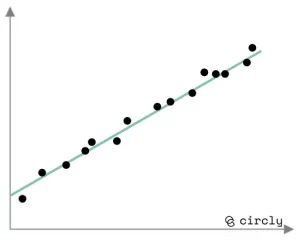
Trendy demand pattern
Dies ist jedoch bei weitem nicht der Fall. Statistische Methoden versagen dabei, unlogische Veränderungen der Kundenwünsche vorherzusehen oder vorherzusagen, wann eine Marktsättigung eintritt.
Zusammenfassend lässt sich sagen, dass eine teilautomatisierte statistische Vorhersage ein zufriedenstellendes Maß an Genauigkeit bietet für:
1. mittel- bis langfristige Planung,
2. gut eingeführte Produkte, die eine stabile Nachfrage haben, und
3. Vorhersage der Gesamtnachfrage
4. Eignet sich nicht zur Absatzplanung einzelner Lagerhaltungseinheiten (SKUs).
Ist es also eventuell doch sinnvoll, in anspruchsvollere Technologien, wie Machine Learning oder künstliche Intelligenz zu investieren?
Maschinelles Lernen für die Bedarfsplanung:
erweiterte Genauigkeit bedeutet Betrachtung der Komplexität
Gesteigerte Computerleistung auf der einen Seite und erhöhte Volatilität der Nachfrage auf der anderen Seite schufen die perfekte Voraussetzungen für einen vermehrten Einsatz von maschinellem Lernen (ML) zur Bedarfsplanung.
Aufbauend auf die bereits vorgestellten statistischen Modellen, nutzt maschinelles Lernen weitere interne und externe Datenquellen, um genauere, datengesteuerte Vorhersagen zu treffen. Sogenannte „ML-Engines“ können sowohl mit strukturierten als auch mit unstrukturierten Daten arbeiten, wie z. B. mit vergangenen Umsatzberichte (historische Daten), Marketingkampagnen, makroökonomischen Indikatoren, Social-Media-Signalen (Retweets, Shares, etc), Wettervorhersagen und mehr.
Doch der Einsatz von maschinellem Lernen lohnt sich. Es wendet automatisierte und komplexe mathematische Algorithmen an, um ohne Eingriff verschiedenste Muster zu erkennen, Bedarfssignale zu erfassen und komplizierte Zusammenhänge in großen Datensätzen zu erkennen.
Intelligente Systeme analysieren nicht nur riesige Datenmengen, sondern trainieren die Modelle kontinuierlich neu und passen sich an ändernde Marktbedingungen an, um so die Volatilität auszugleichen. Diese Fähigkeiten ermöglichen es ML-basierter Software, genauere und zuverlässigere Prognosen in komplexen Szenarien zu erstellen.
Daher ist es auch nicht verwunderlich, dass Unternehmen, die ihre bestehenden Systeme um maschinelles Lernen erweitert haben, von einer Steigerung der Prognosegenauigkeit um 5 bis 15 Prozent (bis zu einer Genauigkeit von 85 und sogar 95 Prozent). Darüber hinaus wurde die Effizienz des einsetzenden Unternehmen aufgrund wegfallender, zeitaufwändigen manuellen Anpassungen und Neukalibrierungen gesteigert.
Um die Vorteile des maschinellen Lernens auszukosten, wird eine ausreichende Rechenleistung und große Mengen an qualitativ hochwertigen Daten benötigt. Andernfalls wird das System nicht in der Lage sein, zu lernen und wertvolle Vorhersagen zu generieren. Des Weiteren sollten Sie auch die zusätzliche Komplexität in Bezug auf die Wartung der Software und die Interpretation der Ergebnisse beachten. Während ML-Modelle ohne menschliches Eingreifen zu Schlussfolgerungen kommen, muss ein Experte bestimmen, welche Faktoren (sog. Features) in das Modell eingespeist werden, welche davon den größten Einfluss auf die Aussagekraft haben und warum das Modell eine bestimmte Vorhersage generiert.
All dies kann bei der eigenen Umsetzung eines solchen Projektes, Ihre Ausgaben für Infrastruktur und Personal in die Höhe treiben. Daher sollten Sie also sicherstellen, dass die Optimierung der Genauigkeit, die damit verbundenen Ausgaben decken oder sich einen Technologiepartner wie Circly mit den genannten Aufgaben beauftragen.
Unternehmen wie Circly übernehmen nicht nur die benötigte Infrastruktur, Erstellung der Modelle und das Instandhalten, sondern optimieren die Modelle ständig, um die besten Ergebnisse zu erzielen.
Hier eine Übersicht, wann maschinelles Lernen definitiv besser funktioniert als traditionelle Statistik:
1. kurze- bis mittelfristige Planung,
2. volatile Nachfragemuster,
3. schnell wechselnde Gegebenheiten & Trends,
4. neue Produkteinführungen.
| Traditionelle Prognosen | Machine Learning Prognosen | Circly’s KI Prognose | |
|---|---|---|---|
| Wie viele Variablen und Datenquellen können berücksichtigt werden? | Das Hinzufügen zusätzlicher Variablen und Quellen erfordert erheblichen Aufwand. | Mehrere Variablen & Quellen können dank der hohen Automatisierung problemlos eingebunden werden. | Eine Vielzahl von Variablen und zur Verfügung gestellten Daten können einfach eingebunden werden. |
| Umfang der manuellen Arbeit: | Hoch | Niedrig | Niedrig |
| Menge der benötigten Daten: | Gering | Groß | Mittel bis Groß |
| Wartungsaufwand: | Gering | Hoch | Gering |
| Technologie-Anforderungen: | Gering | Hoch | Gering bis Mittel |
| Beste Eignung: | Langfristige Planung Etablierte Produkte Stabile Nachfrage |
Mittelfristige Planung Neue Produkte Volatile Bedarfsszenarien |
Mittel- & kurzfristige Planung Wechselnde Faktoren Bestehende Prozesse |
Sie haben Fragen zu möglichen Einsatzgebieten?
Kontaktieren Sie uns und vereinbaren Sie sich Ihr individuelles und unverbindliches Gespräch mit unserer Geschäftsführung.