




Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics ist der Schlüssel zur Optimierung der Nachfrageplanung in einem sich schnell verändernden Markt. Unternehmen müssen auf diese Technologien setzen, da traditionelle Methoden oft nicht ausreichen, um plötzliche Veränderungen im Kaufverhalten der Verbraucher zu erfassen – sei es durch Wetterbedingungen, Social-Media-Trends oder globale Ereignisse. Laut dem IT-Forschungsunternehmen Gartner gehört die Nachfragevolatilität zu den größten Herausforderungen für Führungskräfte, weshalb präzise Prognosen wichtiger denn je sind.
Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics ermöglicht es Unternehmen, riesige Mengen an historischen und aktuellen Daten zu analysieren und genauere Nachfrageprognosen zu erstellen. Diese Technologien helfen dabei, Bestände zu optimieren, Marktveränderungen frühzeitig zu erkennen und fundierte Geschäftsentscheidungen zu treffen. In diesem Artikel zeigen wir, wie Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics die Nachfrageplanung revolutioniert und vergleichen traditionelle statistische Modelle mit modernen, KI-gestützten Ansätzen.
Der Stellenwert von Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics in der Angebotsplanung
Wie Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics die Effizienz steigert: Grundlagen und Methoden
Die Bedarfsprognose ist die Schätzung der wahrscheinlichen zukünftigen Nachfrage nach einem Produkt oder einer Dienstleistung. Der Begriff wird oft austauschbar mit der Bedarfsplanung verwendet, doch letztere ist ein umfassenderer Prozess, der mit der Prognose beginnt, aber nicht auf diese beschränkt ist.
Laut dem Institute of Business Forecasting and Planning (IBF) werden bei der Bedarfsplanung „Prognosen und Erfahrungswerte eingesetzt, um die Nachfrage nach verschiedenen Artikeln an verschiedenen Punkten der Lieferkette zu schätzen.“ Zusätzlich zu den Schätzungen nehmen Bedarfsplaner an der Bestandsoptimierung teil, stellen die Verfügbarkeit der benötigten Produkte sicher und überwachen die Differenz zwischen Prognosen und tatsächlichen Verkäufen.
Die Bedarfsplanung ist der Ausgangspunkt für viele andere Aktivitäten, wie z. B. Lagerhaltung, Versand, Preisprognosen und insbesondere die Angebotsplanung, die auf die Deckung des Bedarfs abzielt und dazu Daten über den voraussichtlichen Wunsch der Kunden benötigt.
Hier kehren wir wieder zur Prognose zurück. So nah wie möglich an der Realität zu sein, ist der Schlüssel zur Verbesserung der Effizienz in der gesamten Lieferkette. Doch wie erreicht man die höchstmögliche Genauigkeit? Die Antwort hängt vom Unternehmenstyp, den verfügbaren Ressourcen und den Zielvorgaben ab.
Vergleichen wir die vorhandenen Optionen: traditionelle statistische Prognosen, Algorithmen für maschinelles Lernen, Predictive Analytics, welches beide Ansätze kombiniert, und Demand Sensing als unterstützendes Tool.
Traditionelle statistische Prognosen vs. Bedarfsprognosenmethode Maschinelles Lernen Predictive Analytics
Traditionelle statistische Methoden (TSM) gibt es schon seit Ewigkeiten und sie sind nach wie vor ein fester Bestandteil von Prognoseprozessen in der Produktion und im Handel.
Der Unterschied zu früheren Berechnungen besteht lediglich darin, dass diese inzwischen automatisch von Softwarelösungen durchgeführt werden. Zum Beispiel können in Excel Zeitreihenprognosen für Umsätze und Trends erstellt werden.
Um die Zukunft zu prognostizieren, nutzt die Statistik Daten aus der Vergangenheit. Deshalb werden statistische Prognosen oft als „Historische Auswertung“ bezeichnet. Traditionelle Prognosen sind immer noch die populärste Methode, um Verkäufe vorherzusagen. In der Regel lassen sich Bedarfsplanungslösungen, die auf statistischen Verfahren basieren, nahtlos in Excel und bestehende Enterprise Resource Planning (ERP)-Systeme durchführen, ohne dass zusätzliches technisches Fachwissen erforderlich ist. Die fortschrittlichsten Systeme können Saisonalität und Markttrends berücksichtigen sowie zahlreiche Methoden zur Feinabstimmung der Ergebnisse anwenden.
Zu beachtende gilt, dass eine wichtige Voraussetzung für die statistische Vorhersagegenauigkeit die Stabilität des Marktes ist. Die Auswertung geht davon aus, dass sich die Geschichte wiederholt: Situationen, die vor zwei oder drei Jahren aufgetreten sind, werden sich wiederholen.
Bedarfsmuster, die statistisch gut bemessen werden können:
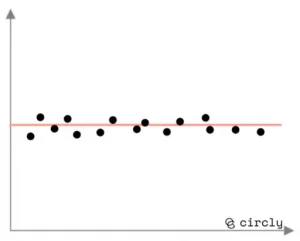
Constant demand curve
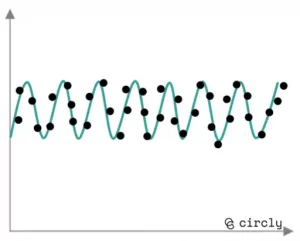
Seasonal demand pattern
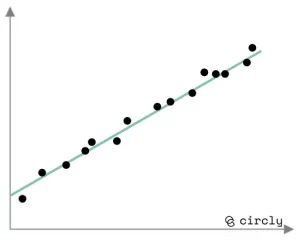
Trendy demand pattern
Dies ist jedoch bei weitem nicht der Fall. Statistische Methoden versagen dabei, unlogische Veränderungen der Kundenwünsche vorherzusehen oder vorherzusagen, wann eine Marktsättigung eintritt.
Zusammenfassend lässt sich sagen, dass eine teilautomatisierte statistische Vorhersage ein zufriedenstellendes Maß an Genauigkeit bietet für:
1. mittel- bis langfristige Planung,
2. gut eingeführte Produkte, die eine stabile Nachfrage haben, und
3. Vorhersage der Gesamtnachfrage
4. neue Produkteinführungen.
| Traditionelle Prognosen | Machine Learning Prognosen | Circly’s KI Prognose | |
|---|---|---|---|
| Wie viele Variablen und Datenquellen können berücksichtigt werden? | Das Hinzufügen zusätzlicher Variablen und Quellen erfordert erheblichen Aufwand. | Mehrere Variablen & Quellen können dank der hohen Automatisierung problemlos eingebunden werden. | Eine Vielzahl von Variablen und zur Verfügung gestellten Daten können einfach eingebunden werden. |
| Umfang der manuellen Arbeit: | Hoch | Niedrig | Niedrig |
| Menge der benötigten Daten: | Gering | Groß | Mittel bis Groß |
| Wartungsaufwand: | Gering | Hoch | Gering |
| Technologie-Anforderungen: | Gering | Hoch | Gering bis Mittel |
| Beste Eignung: | Langfristige Planung Etablierte Produkte Stabile Nachfrage |
Mittelfristige Planung Neue Produkte Volatile Bedarfsszenarien |
Mittel- & kurzfristige Planung Wechselnde Faktoren Bestehende Prozesse |
Sie haben Fragen zu möglichen Einsatzgebieten?
Haben Sie Fragen zur Umsetzung in Ihrem Unternehmen? Kontaktieren Sie uns für eine unverbindliche Beratung!
Weiterführende Quelle: https://ieeexplore.ieee.org/abstract/document/10590108
4. Eignet sich nicht zur Absatzplanung einzelner Lagerhaltungseinheiten (SKUs).